- Полезные плагины / расширения Chrome
- Инструмент визуализации структурированных данных: Gruff
- Инструменты, которые позволяют вам получать информацию из текста
- Ключевые вынос
Поисковые системы используют структурированные данные, чтобы определить, какие объекты находятся на вашей веб-странице. Они также могут сделать это, используя другие методы, такие как обработка естественного языка (NLP) и машинное обучение.
Эта статья познакомит вас с различными инструментами, которые помогут вам идентифицировать сущности на веб-странице. Эти инструменты включают в себя:
- Интересные плагины / расширения Chrome, которые позволяют вам видеть объекты, полученные из структурированных данных / разметки, когда вы просматриваете любую веб-страницу
- Фантастический инструмент визуализации для графов объектов, которые можно запускать локально на вашем компьютере
- Инструменты, которые извлекают сущности на веб-странице, используя в основном методы обработки естественного языка (NLP)

Как видеть ваши веб-страницы, как это делает поисковая система
Полезные плагины / расширения Chrome
Существует несколько плагинов для Chrome, которые чрезвычайно полезны для понимания (и фактического просмотра) того, что структурированные данные находятся на веб-странице. Ниже показаны используемые мной расширения Chrome, перечисленные под ключевым словом, используемым для их поиска с помощью Интернет-магазин Chrome поиск.

Вот ссылки на каждое расширение:
Есть много преимуществ использования этих плагинов. С одной стороны, они действительно дают вам хорошее представление о том, кто использует какую разметку на своих веб-сайтах, когда вы ежедневно просматриваете веб-страницы. Когда вы видите, что эти маленькие микроданные и значки структурированной разметки появляются в вашем браузере, вам нужно всего лишь щелкнуть мышью, чтобы сразу увидеть, какие виды разметки и метаданных находятся на странице.
Другое преимущество состоит в том, что некоторые из этих расширений сканируют JavaScript, поэтому вы можете видеть все виды интересной информации, которую вы не могли видеть, если бы вы просматривали те же самые страницы. Богатый инструмент для тестирования фрагментов Google ,
Попытка отобразить объем информации, предоставляемой всеми этими расширениями на одном снимке экрана, невозможна, поэтому я решил включить только несколько примеров, разбитых на несколько снимков экрана.
( Примечание : тот факт, что на одном снимке экрана отображается слишком много информации, свидетельствует о росте структурированных данных в Интернете, поскольку последний написал по теме 2 года назад. Объем информации, доступной на средней веб-странице, по сравнению с 2012 годом увеличился на несколько порядков.)
Три скриншота ниже обеспечивают выборку видов информации, получаемой с помощью расширений микроданных. (Все можно увеличить, щелкнув.) Несмотря на то, что информация довольно схожа для всех трех расширений, неплохо иметь несколько доступных инструментов на случай, если один обнаружит что-то, что другие пропустили.
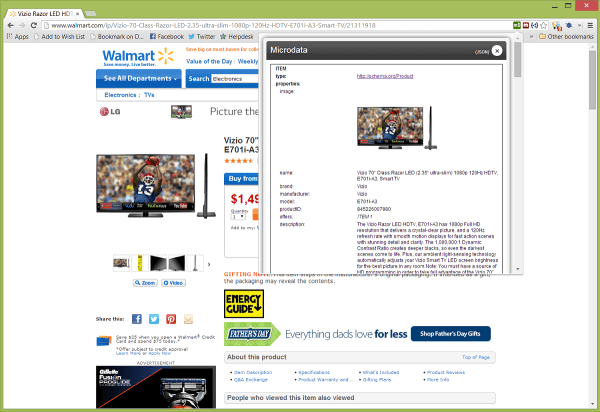
Информация предоставлена расширением инспектора микроданных. (Нажмите, чтобы увеличить.)
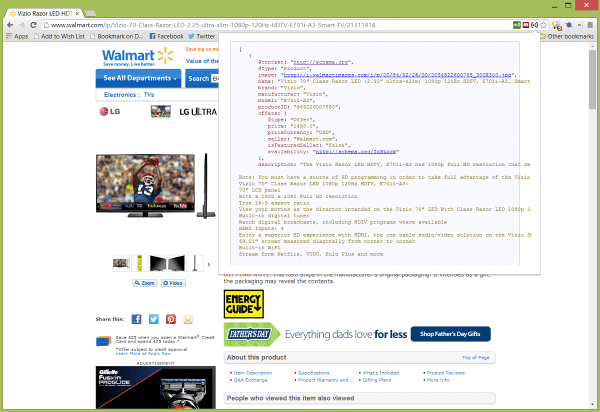
Информация предоставлена расширением Microdata / JSON-LD sniffer. (Нажмите, чтобы увеличить.)
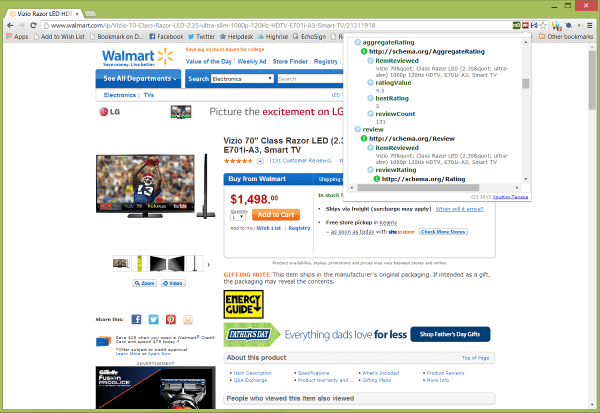
Информация предоставлена расширением Semantic Inspector. (Нажмите, чтобы увеличить.)
Все три плагина определены schema.org Разметка товара , включая свойства для изображения, названия, бренда, производителя, модели, идентификатора продукта, предложений и описания. Они также определили разметку на странице для обзоров и оценок.
Маркетологи, желающие реализовать собственную структурированную разметку, могут быть наиболее заинтересованы в Расширение для микроданных / JSON-LD (средний скриншот выше), так как он предоставляет информацию в удобном HTML-виде.
SEO-инспектор META обеспечивает еще более высокий уровень просмотра данных страницы:
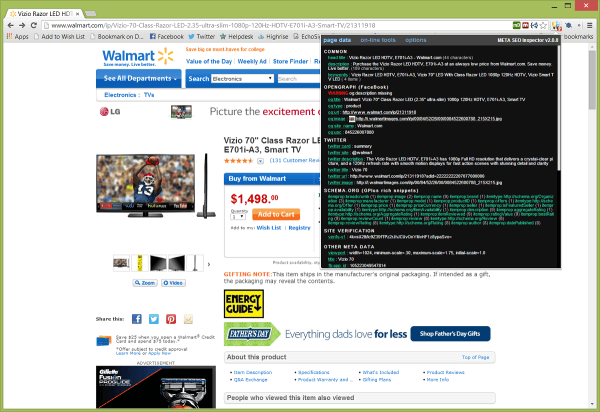
Информация предоставлена расширением инспектора META SEO. (Нажмите, чтобы увеличить.)
Как показано на снимке экрана выше, инспектор META SEO позволяет просматривать все виды метаданных, предоставляемых поисковым системам, начиная от устаревших, но все еще используемых тегов метаданных, до информации schema.org, Facebook Open Graph, инструментов / карт Twitter и многого другого.
Последнее расширение, которое я собираюсь охватить здесь, называется Green Turtle RDFa. Это расширение предоставляет не только полный список информации о субъектах-предикатах-объектах на веб-странице, но и визуализацию этой информации. Вот представление информации, которую Green Turtle почерпнула со страницы продукта Walmart, которую мы использовали в качестве примера:
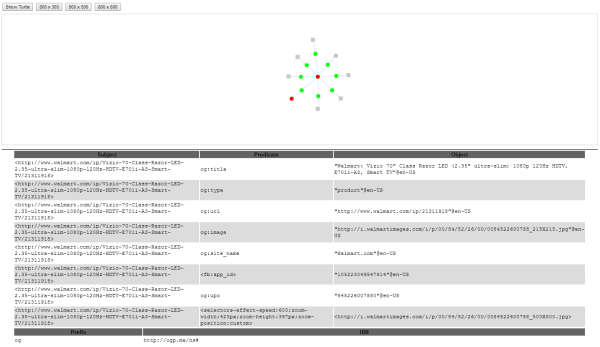
Информация предоставлена Зеленой черепахой. (Нажмите, чтобы увеличить.)
При правильных настройках этот инструмент также извлекает микроданные. Чтобы включить эту функцию для этого расширения после его загрузки, необходимо выполнить следующие действия:
Загрузив расширение Green Turtle в браузер Chrome, перейдите в «Инструменты» -> «Расширения» и найдите его в списке расширений. Выберите «Опции», затем установите флажок «Включить микроданные».
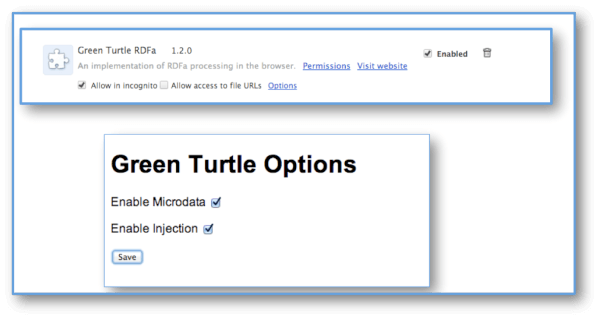
Включение микроданных (а также RDFa в Green Turtle
Теперь, когда вы включили анализ RDFa и микроданных для плагина Green Turtle, вы сможете увидеть много информации. Проверьте новые результаты для той же страницы продукта Walmart:
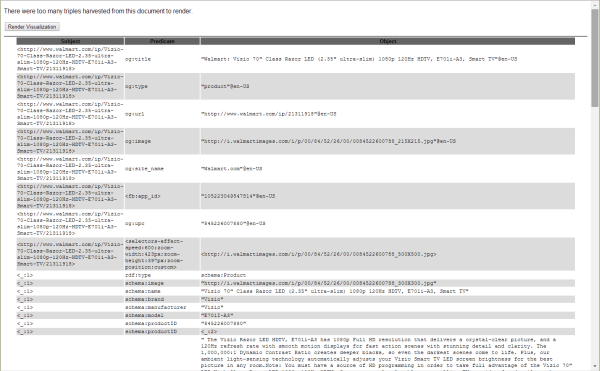
Информация о Зеленой черепахе с включенными микроданными. (Нажмите, чтобы увеличить.)
Инструмент визуализации структурированных данных: Gruff
Гриф это инструмент, который скачать бесплатно (Mac или ПК) и позволяет визуализировать, какие структурированные данные (или тройки - объекты данных, состоящие из объекта-предиката-объекта) собираются с веб-страницы. График ниже (извлечено из недавняя статья Land Search Engine, которую я написал ) даст вам представление о том, какую информацию может предоставить вам Gruff.
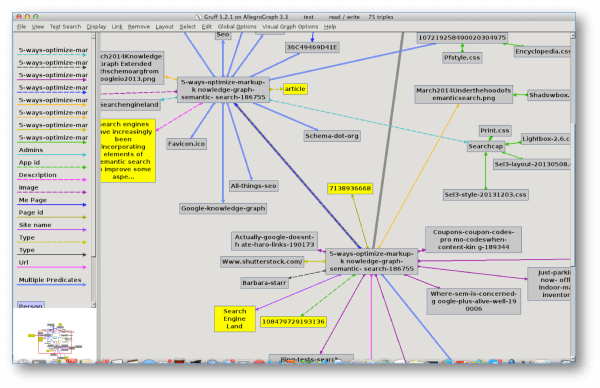
Иллюстрации структурированной информации, полученной от Gruff, на основе статьи из Search Engine Land. (Нажмите, чтобы увеличить.)
Чтобы использовать Gruff, вы должны сначала скачать здесь , Чтобы запустить его локально и использовать более простую установку, я бы порекомендовал загрузить версию 3.3 (вы увидите оба варианта при выборе варианта загрузки).
После установки Gruff вам нужно будет создать «Новый Triple-Store» в меню «Файл». После завершения вы можете извлечь данные веб-страницы, выбрав Файл -> Извлечь данные микроформата / RDFa с веб-страницы, а затем введя URL-адрес в соответствующее поле. (Оставьте поле Имя графика пустым.)
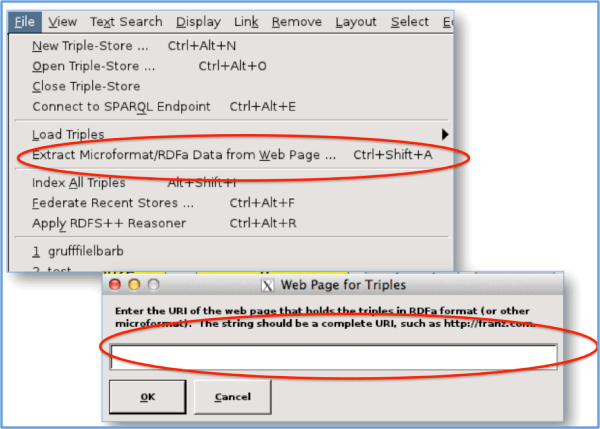
Когда программа закончит извлечение данных, перейдите на вкладку «Отображение» и выберите последний параметр, «Показать тройки одного графика». Это должно вызвать карту визуализации данных (как показано выше).
Инструменты, которые позволяют вам получать информацию из текста
(Смотрите, какие объекты в вашем тексте - НЛП Инструменты)
TextRazor это API, который анализирует ввод текста, чтобы определить информацию о конкретных объектах в этом тексте. С помощью этого инструмента вы можете «извлечь кто, что, почему и как» из текста веб-страниц, твитов, электронных писем и т. Д. Чтобы увидеть, как это работает, посмотрите их демонстрационная страница и введите текст.
В качестве примера, вот что пришло в голову TextRazor при анализе первых двух абзацев один из моих предыдущих столбцов (нажмите на картинку, чтобы увеличить):
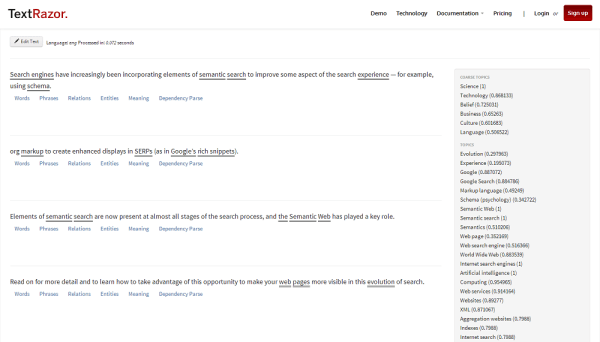
TextRazor анализирует текст и извлекает информацию об объектах. (Нажмите, чтобы увеличить.)
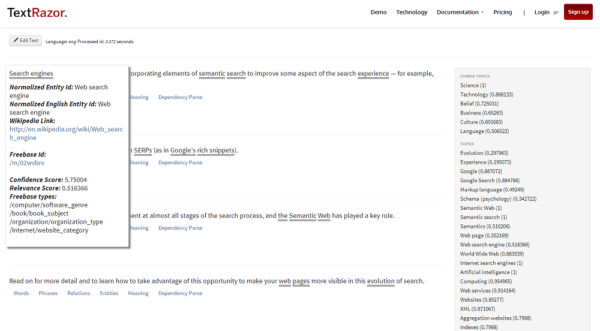
Когда вы наводите курсор на объекты, идентифицированные TextRazor, всплывает дополнительная информация об этом объекте, включая ссылку в Википедии и идентификатор Freebase. (Нажмите, чтобы увеличить.)
Другие полезные инструменты и API для извлечения именованных объектов из текста включают в себя:
С этими инструментами может быть интересно поиграть, обеспечивая при этом полезное понимание того, как сущности и графы сущностей могут быть получены как из структурированных, так и из неструктурированных источников информации на веб-странице.
Ключевые вынос
- Понимание того, что сущности могут быть получены из структурированной, полуструктурированной, а также неструктурированной информации на странице, может быть чрезвычайно полезным при переходе к пониманию семантического поиска.
- Потратьте некоторое время, просто играя с этими инструментами, и вы обнаружите, что задача и концепция менее устрашающие, чем могут показаться.
- Если это кажется сложным, это потому, что это сложно! Однако в целях простого использования технологии для получения представления о том, какие объекты находятся на странице (это все, что вам нужно знать, если вы не хотите стать исследователем или создавать инструменты), это просто полезно и весело.
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,
Об авторе
Похожие
SEO инструменты... инструменты в тесте. У меня всегда есть подробная информация о моем опыте с программными продуктами отзывы написано. Чтобы дать вам обзор инструментов SEO, я создал эту страницу. Отсюда вы можете приступить к тестированию инструментов по кратчайшему маршруту. Ведущее программное обеспечение в немецкоязычных странах. SEO ошибки, которые стоят вам денег
Как известно всем, кто имеет бизнес в Интернете, инвестиции в SEO жизненно необходимы, если вы хотите добиться успеха в Интернете. Без SEO вы полагаетесь исключительно на удачу, чтобы получить рейтинг для тех ключевых ключевых слов, которые описывают ваш бизнес и продукты и услуги, которые вы продаете. Однако, что вам нужно понять, так это то, что с SEO вы можете совершить множество критических ошибок, которые в конечном итоге начнут стоить вам серьезных денег. В сегодняшнем руководстве 25 SEO-расширений для Chrome
Вот коллекция из 25 расширений Chrome SEO, которую должны знать и использовать все менеджеры сообщества и специалисты по маркетингу. WooRank предлагает вам совершенно бесплатные SEO отчеты. Установите это дополнение и получите SEO-отчеты о сайтах, которые вы хотите. WooRank автоматически анализирует ваш сайт и генерирует полный отчет SEO за 5 секунд. SEO-отчет WooRank включает в себя анализ следующих критериев: Посетители. Бюджетные расширения Google Chrome для SEO
... позволяют извлечь некоторые термины, найденные на вашем веб-сайте, и выполнить поиск по тегам. Вы также можете выполнить исследование ключевых слов и проверить свой контент и посмотреть, не может ли какой-либо из них быть плагиатом. Лучшие инструменты SEO
Лучшие инструменты SEO для исследования ключевых слов Keywordtool.io В результате, что он предлагает нам Keywordtool.io Мы найдем 10 самых важных слов, связанных с вводимым термином, а затем 10 самых важных ключевых слов для каждой буквы алфавита. Это очень мощный инструмент, но платный. Бесплатная версия позволяет нам видеть только ключевые слова без их объема. В качестве дополнительного бонуса, 5 SEO плагинов для WordPress, которые помогут вам позиционировать
... инструменты, как Xenu и Кричащая лягушка с помощью которого вы можете обнаружить их, а также расширения для нашего браузера, как Проверьте мои ссылки , но в том случае, если мы хотим сделать это из самого WordPress, ускоряя время, которое мы тратим на комментируемые Инструмент SEO-анализа с Forecheck
SEO-агентства, веб-мастера, владельцы сайтов - сегодня инструменты SEO-анализа являются необходимыми условиями для успешного функционирования веб-сайтов и рентабельности инвестиций. Вопрос только в том, какой инструмент SEO анализа вам нужен? Ответ Типология ключевых слов: какие типы ключевых слов выбрать для своей стратегии SEO?
Поиск и подбор ключевых слов является неотъемлемой частью любой SEO-кампании. С соответствующими ключевыми словами, которые соответствуют цели вашего сайта, вы можете получить лучшие результаты поиска, увеличить трафик и повысить коэффициент конверсии . Но как найти хорошие ключевые слова среди множества терминов и выражений, относящихся к вашей отрасли? Одним из первых шагов является выявление различных типов ключевых слов с их сильными сторонами и ограничениями. Сколько времени нужно, чтобы увидеть результаты моей стратегии SEO?
Это только естественно. Первое, что вы хотите знать после того, как наняли эксперта по цифровому маркетингу, который поможет вам с вашей стратегией SEO: сколько времени потребуется, чтобы увидеть результаты? Хотя это справедливый вопрос, это все равно, что спрашивать издателя, когда их последняя книга начнет приносить прибыль. Это зависит от множества факторов, таких как, на 10 блестящих SEO инструментов, плагинов и хаков, которые вам нужно использовать сейчас
... которые вы (в основном) никогда не видели раньше» в нашем офисе в Ньютоне, штат Массачусетс. Мы были рады не только принять у себя событие Но еще более взволнован, чтобы изучить несколько новых способов использования инструментов и плагинов SEO в нашем постоянно растущем арсенале. Главная цель Дэна состояла в том, чтобы предоставить каждому участнику хотя бы один новый инструмент или один новый способ использовать инструмент, который они Найти ключевые слова - стратегически настроить SEO
11 декабря 2016, Автор: Wolff Trace | Бьянка Вольф Ключевые слова - это S, E и O в SEO. Но как найти правильные ключевые слова? Поиск правильных ключевых слов имеет основополагающее значение для успеха SEO сайта. Но как бы банально ни звучала эта тема: вопрос возникает в нашей повседневной практике SEO снова и снова. Итак, вот небольшое стратегическое руководство по поиску правильных ключевых слов, их анализу и поиску подходящих
Комментарии
Какие инструменты вам нужно знать, какие ключевые слова конвертируют больше всего?Какие инструменты вам нужно знать, какие ключевые слова конвертируют больше всего? # 1 - Google Analytics [Минут 2:14] Ранее мы видели обычный и простой процесс конверсии, который проходил от ключевых слов к страницам результатов Google, затем переходил на целевую страницу нашего веб-сайта и впоследствии Без надежных данных для создания SEO-кампаний, как они узнают, какие ключевые слова работают на их сайтах, а какие нет?
Без надежных данных для создания SEO-кампаний, как они узнают, какие ключевые слова работают на их сайтах, а какие нет? Один из наиболее неприятных аспектов зашифрованного поиска заключается в том, что он не влияет на данные PPC, а только на обычный поиск. Некоторые предполагают, что обновление для безопасного поиска также должно подталкивать владельцев сайтов к тому, чтобы они тратили больше средств на свои кампании PPC, чтобы получить доступ к данным, которые когда-то были бесплатными. Но как вы узнаете, какие правильные инструменты SEO для услуг, которые разрабатывает ваша команда?
Но как вы узнаете, какие правильные инструменты SEO для услуг, которые разрабатывает ваша команда? Проверьте ниже список, который мы подготовили с семью из них, которые не могут быть исключены из вашего агентства и ваших проектов! Извлекайте важные данные с помощью инструментов SEO Чтобы добиться технических улучшений на сайтах ваших клиентов и получить хорошее место размещения в Google, вам нужно заняться поиском соответствующей информации об эффективности страниц, Вам интересно, какие шаги вы должны предпринять, чтобы стать экспертом по SEO?
Вам интересно, какие шаги вы должны предпринять, чтобы стать экспертом по SEO? Отлично, потому что это руководство покажет вам все, что вам нужно знать. Стать экспертом по SEO не так сложно, как вы думаете. Вот шаги, которым я следовал, и я расширяюсь каждый день, чтобы решить свою задачу стать лучшим SEO на Майорке. Мы идем туда Если вам нужен SEO для вашего проекта, и вы хотите нанять меня, давай поговорим Эти и многие другие параметры необходимы, чтобы помочь вам найти ресурс, который вы ищете - но почему это важно?
Эти и многие другие параметры необходимы, чтобы помочь вам найти ресурс, который вы ищете - но почему это важно? Почему одна конкретная структура URL лучше другой? Хотите без каких-либо обязательств узнать, какие ключевые слова Google приносят вам максимальный оборот?
Хотите без каких-либо обязательств узнать, какие ключевые слова Google приносят вам максимальный оборот? Свяжитесь со мной сейчас через страница контактов , Я использую конкурентоспособную почасовую ставку Общая почасовая заработная плата старшего SEO-специалиста на оплачиваемой работе составляет приблизительно 35 евро, моя почасовая ставка для фрилансера временно составляет всего 50 евро, Как вы можете начать с оптимизации вашего сайта и какие плагины WordPress SEO могут помочь вам в этом?
Как вы можете начать с оптимизации вашего сайта и какие плагины WordPress SEO могут помочь вам в этом? На этой странице вы найдете ответы. SEO и WordPress: отличное сочетание Если вы смотрите исключительно на SEO, WordPress - одна из лучших систем управления контентом, которую вы можете использовать. Настройки по умолчанию гарантируют, что поисковые системы могут легко сканировать ваши сообщения, страницы и категории. Но это не значит, что вам больше не нужно ничего Вы не устали от необходимости посещать анонимную сессию, чтобы контролировать позиции в определенных ключевых словах, которые приносят вам трафик в Google, знаете ли вы, повышаетесь или понижаетесь?
Вы не устали от необходимости посещать анонимную сессию, чтобы контролировать позиции в определенных ключевых словах, которые приносят вам трафик в Google, знаете ли вы, повышаетесь или понижаетесь? Ну да, но благодаря этому плагину вы можете ежедневно просматривать свои позиции в определенной стране или домене Google с графиками и статистикой, упорядоченными по дате, чтобы точно знать, когда именно вы повышаете или понижаете позиции в Google в своем WordPress без должны использовать другие внешние Ключевые слова и фразы (мета ключевые слова ключевые слова) и как часто они появляются на странице?
Сколько времени вам нужно, чтобы просмотреть веб-сайт и получить всю необходимую информацию?
Сколько времени вам нужно, чтобы просмотреть веб-сайт и получить всю необходимую информацию? Вам даже нужно потратить много времени на сайте, прежде чем завершить требуемый призыв к действию? Эти факторы определяют, сколько времени тратят на ваш сайт новые и возвращающиеся посетители. Теперь вы знаете, как правильно использовать эти виды практики, чтобы оказать положительное влияние на SEO, чего вы ждете, чтобы улучшить их?
Теперь вы знаете, как правильно использовать эти виды практики, чтобы оказать положительное влияние на SEO, чего вы ждете, чтобы улучшить их?
Вопрос только в том, какой инструмент SEO анализа вам нужен?
Но как найти хорошие ключевые слова среди множества терминов и выражений, относящихся к вашей отрасли?
Сколько времени нужно, чтобы увидеть результаты моей стратегии SEO?
Первое, что вы хотите знать после того, как наняли эксперта по цифровому маркетингу, который поможет вам с вашей стратегией SEO: сколько времени потребуется, чтобы увидеть результаты?
Но как найти правильные ключевые слова?
Какие инструменты вам нужно знать, какие ключевые слова конвертируют больше всего?
Без надежных данных для создания SEO-кампаний, как они узнают, какие ключевые слова работают на их сайтах, а какие нет?
Но как вы узнаете, какие правильные инструменты SEO для услуг, которые разрабатывает ваша команда?
Но как вы узнаете, какие правильные инструменты SEO для услуг, которые разрабатывает ваша команда?
Вам интересно, какие шаги вы должны предпринять, чтобы стать экспертом по SEO?