- Канонические и другие метки
- 1. Канонический с rel = prev и rel = next
- 1.2. rel = prev, rel = next и canonical
- 2. Канонический с hreflang
- 2.1. hreflang
- 2.2. Hreflang и канонический
- 3. Канонический с hreflang и xdefault
- 3.2. x-default и канонический
- 3.3. hreflang, канонический и синдикация контента на одном языке между порталами
- Дистиллированная проба
- Эссе Серхио Редондо
- 4. Канонический с усилителем
- 4.2. Канонический + усилитель
- 5. Canonical с мобильной версией
- 5.2. мобильный + канонический
- 5.3. Canonical с усилителем и мобильной версией
- 6. Канонический с noindex
- 6.2. Noindex и канонический:
- 7. Канонический с robots.txt
- 7.1. Приложение: Запрещает ли предотвращение индексацию?
Каноническая - это машинная директива, работающая как тег <meta>, которая помещается в поле <head>, поддерживается bing!, Google и Yahoo и предназначена для работы с дублирующимся контентом, указывая в нем, что такое исходный контент. Родившийся в 2009 году в разгар синдикации контента, это способ помочь поисковым системам выбрать, что является оригинальным контентом, и позволить им правильно идентифицировать оригинального издателя этого.
Канонические и другие метки
- Канонический с rel = prev и rel = next
- Канонический с hreflang
- Канонический с hreflang и xdefault
- Канонический с усилителем
- Canonical с мобильной версией
- Канонический с noindex
- Канонический с robots.txt
Каноническая директива является директивой рекомендуемого соответствия, но она не обязательна, поскольку они уже неоднократно предупреждали, что если сигналы ясны в другом смысле, они будут отображать в качестве основного контента URL-адрес, даже если он имеет канонический для другого, в свою очередь ... Если вам нужно больше информации, здесь Вы можете найти ее.

В общем, использование canonical rel рекомендуется в следующих сценариях:
- Перед разными URL-адресами (особенно теми, которые идентифицированы с параметрами) сообщите машине, которая является оригиналом.
- Перед распространением контента определите, какой домен является поставщиком контента.
- Столкнулся с сосуществованием разных протоколов (http, https) или ошибками при создании домена (www. И без www) или перед разными доменами (senormunoz.es и senormunoz.com, оба открыты для индексации и оба с одинаковым содержимым)
В этой статье мы покажем вам различные возможности, позволяющие сосуществовать или нет канонической метке цели с другими метатегами, такими как rel = prev и rel = next, rel = noindex, amphtml, альтернатива мобильного телефона, ...
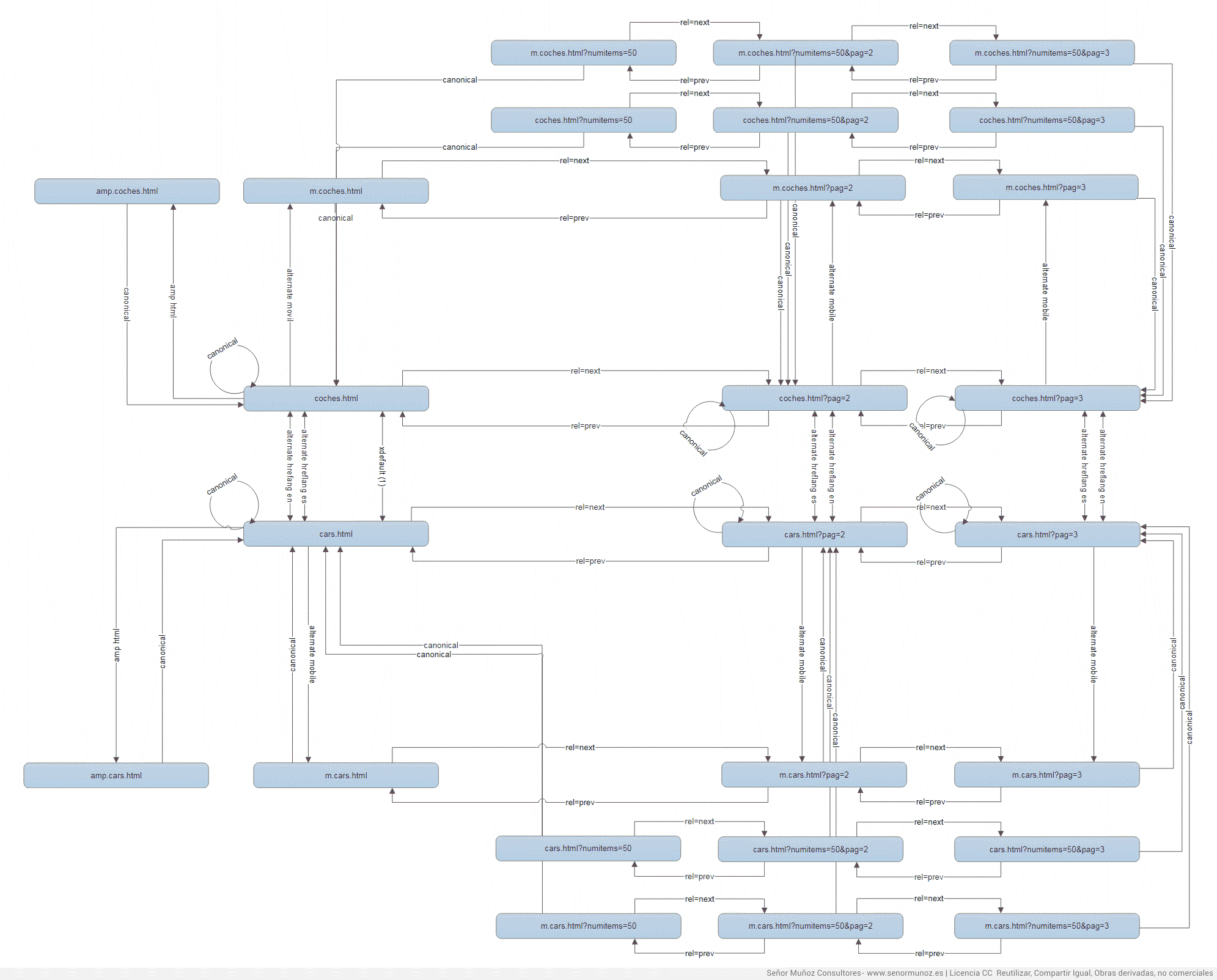
канонический усилитель чередование
1. Канонический с rel = prev и rel = next
1.1. rel = prev и rel = next
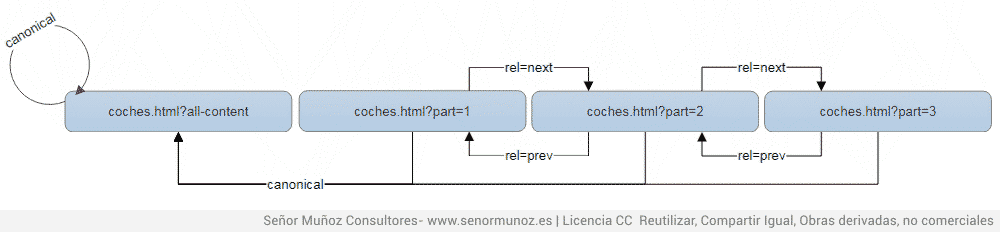
Директива rel = prev и rel = next - это способ указать поисковой системе, что мы сталкиваемся с нумерацией содержимого. То есть контент рассредоточен по разным URL-адресам, имеющим определенный порядок. Преимущество заключается в том, чтобы рассказать поисковой системе, как управлять содержимым страницы. У него есть два сценария:
- страница без URL, на которой добавлено все содержимое
- страница с URL, на которой добавлено все содержимое.
1.2. rel = prev, rel = next и canonical
1) Если у нас есть страница без совокупного URL, она будет принимать только rel = prev и rel = next. Это не должно быть rel = canonical.

rel = канонический с нумерацией страниц, rel = prev и rel = next
2) Каноническое может использоваться вместе с rel = prev и rel = next, когда нам нужно установить каноническую версию страниц, например, когда мы находим параметры в этих URL-адресах.

rel = канонический с нумерацией страниц rel = prev и rel = next и сам канонический.
Хотя этот параметр не имеет значения или не рекомендуется руководящие принципы Это тоже не противопоказано, так что можете поставить или нет.
3) Каноническое и перекрестное разбиение на страницы между последовательными страницами и списками. Мы должны указать канонические символы из URL-адресов с параметрами и разбиение на страницы на URL-адреса без параметров, разбитых на страницы.
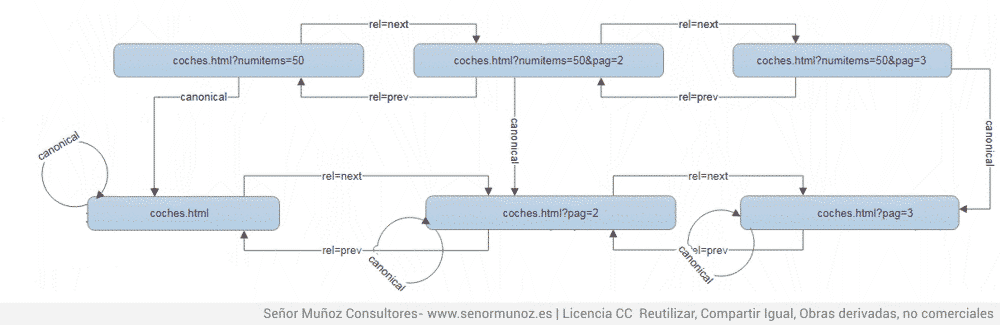
Paginaciones и canónicasl с параметрами
4) Однако следующее является гораздо более нормальным, когда разбиение по страницам с параметрами (в данном случае, такими параметрами, как numitems, который не требует позиционирования) на URL-адрес без дополнительных параметров, чем простое разбиение на страницы. Если у нас есть страница с агрегированным URL-адресом, на разных страницах должен быть указан rel = canonical для агрегированной версии.
rel = canonical с подкачкой страниц rel = prev и rel = next и URL, объединяющий все содержимое.
2. Канонический с hreflang
Возможно, одна из самых сложных частей, так как интересно посмотреть, как каноническое и hreflang, будучи в состоянии совпадать, на самом деле не работают вместе. Мы уже знаем, что каноническое было изобретено, чтобы попытаться бороться с дублированным содержимым, но давайте посмотрим, что такое hreflang раньше.
2.1. hreflang
Hreflang - это способ указать поисковой системе, что две страницы одинаковы, но ориентированы на 1) разные страны 2) разные языки 3) разные страны и языки. Он основан на ISO 639-1 Выгода очевидна: вы можете ориентироваться на разные рынки одним языком. Hreflang помогает определить, какой URL относится к слову на определенном языке или стране или стране и языке. У hreflang есть два соображения:
- должен иметь возвращаемый URL (то есть, если url-language1.htm указывает на url-language2.htm, поскольку url-language2.htm также должен указывать на url-language1.htm
- должен указывать на себя (url-language1.htm будет указывать на hreflang, соответствующий url-idioma1.htm)
2.2. Hreflang и канонический
- может не существовать канонический
- если каноническое существует, оно должно совпадать с hreflang той версии, в которой мы находимся.
- Если есть копия, она не несет hreflang, но канонична оригинальной версии.
- если есть параметр, который 1) должен упорядочить содержимое (пример: параметр сортировки) или 2) содержимое не изменяется (пример: идентификатор сеанса) и, кроме того, 3) не является необходимым для нашей индексации, потому что мы не заинтересованы в индексации, что URL (пример: в URL-адресе автомобилей отображается только SEAT, который мы могли бы индексировать, чтобы URL-адрес позиционировался как "SEAT cars") , не содержит hreflang , но каноничен URL-адресу без параметров .
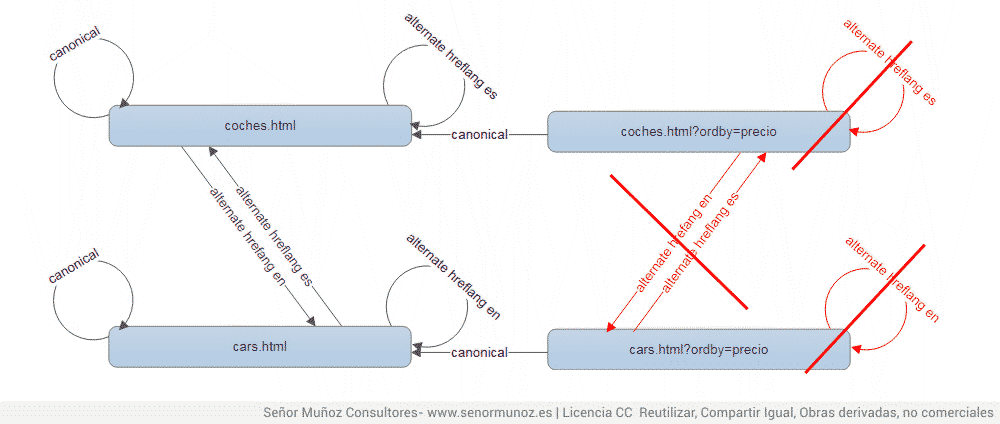
rel = альтернативный hreflang языка и rel = канонический
3. Канонический с hreflang и xdefault
3.1. х-умолчанию
Параметр x-default связан с hreflang (не может использоваться отдельно) и служит для того, чтобы сообщить Google, где мы хотим, чтобы он был пользователем, который не представлен ни одним из идиоматических URL-адресов / стран / обоих. Сначала мы отправили его на URL-адрес для устранения неоднозначности, но со временем также было принято решение сообщить поисковой системе: «эй, у меня нет этой комбинации, поэтому покажите ему этот URL».
3.2. x-default и канонический
Как мы уже говорили ранее, вы всегда должны сопоставлять канонический URL с одним из URL-адресов hreflang (и Джон Мюллер прокомментировал это). этот пост от Google + ). В этом примере канонические ссылки указывают на себя в каждой из версий, поскольку версии для Великобритании и США представляют собой два URL-адреса с рабочим контентом для каждой из отмеченных стран и их соответствующего языка (en-UK и en-US) ,
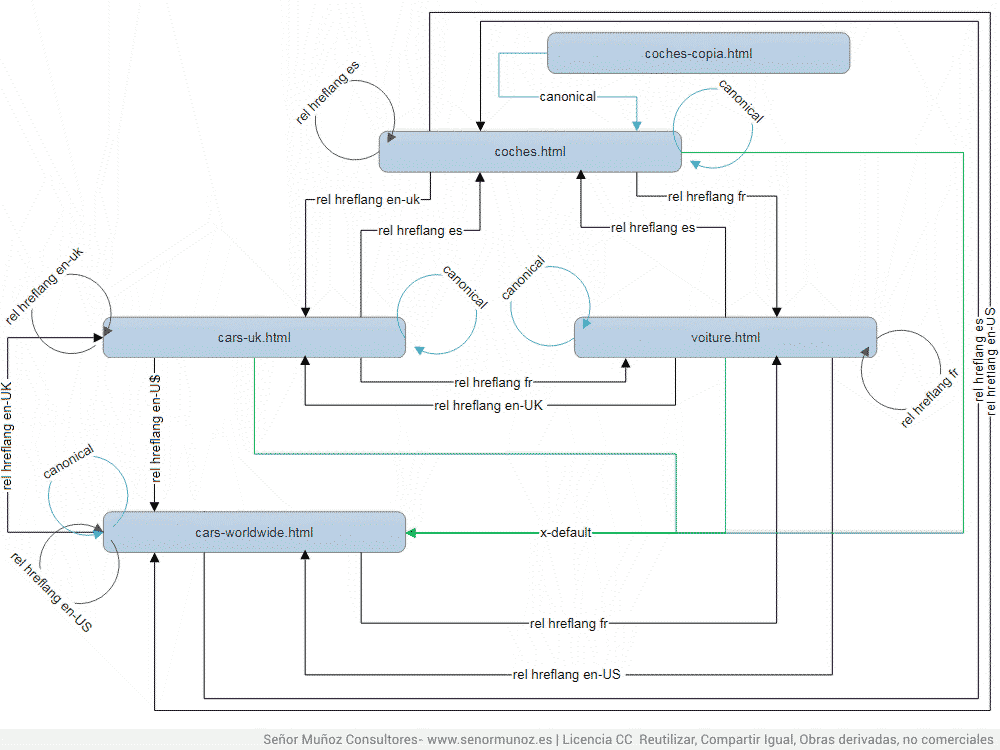
rel = alternate hreflang x-default и canonical
3.3. hreflang, канонический и синдикация контента на одном языке между порталами
Тем не менее, есть случай, когда очевидное использование канонического не так, как ожидается. Это (я говорю вам по секрету, это заняло несколько дней Серхио Редондо , сервер и со специальной помощью Джанлука Фиорелли , Фернандо Макиа , Алейда Солис , Дэвид Кампании , Карлос Эстевес , Иньяки Уэрта и Дэвид Мартин кому я благодарен за то, что терпел меня и заставлял меня пересматривать)
До этого видео дистиллированный говорить о предмете
Как мы уже говорили, мы находимся в особой ситуации, когда нам необходимо уточнить, что мы делаем, если они являются копиями содержимого на одном языке. Представьте себе такую ситуацию, когда следующее: исходный контент создается веб-сайтом в Испании, который точно копируется на веб-сайты Перу, Мексики и Аргентины (безразлично, если это домен с языковыми подпапками, домен с языковыми поддоменами или разные домены для каждой из стран). Кроме того, было решено, что веб с доменом, завершенным в .com, является релевантным веб-сайтом для любого поиска за пределами указанных стран (Перу, Мексика и Аргентина), поэтому, если поисковая система выполняет поиск в google.co (Google Колумбия), то, что Google должен показать вам, является результатом домена .com, а не domain.pe, com.ar или com.mx), поэтому domain.com - это тот, который имеет x-default.
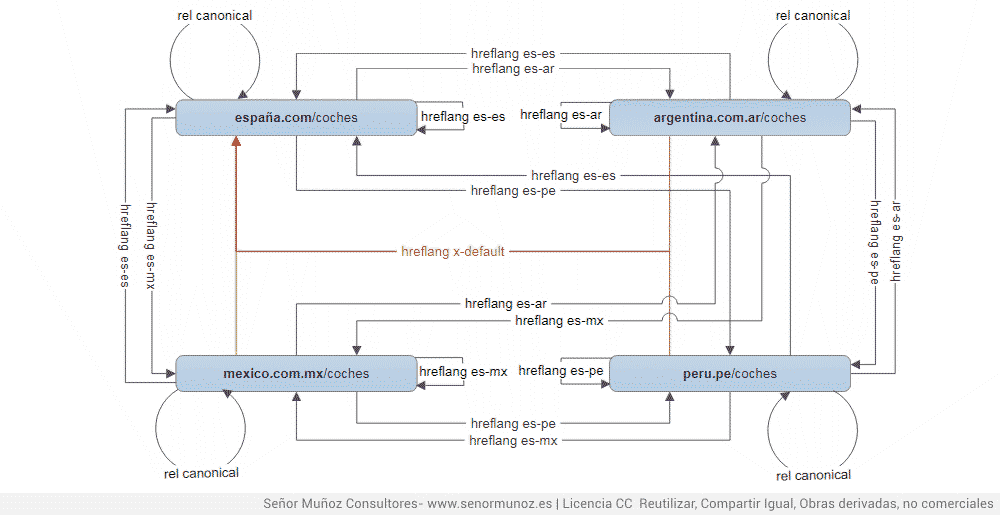
rel = канонический с тем же языком и разными странами плюс x-default и hreflang
Ключ заключается в том, что, как вы можете видеть, все домены, опять же, сами ссылаются на канонические (как это было в случае, когда содержимое было на других языках).
Дистиллированная проба
В тесте, который подвергся дистилляции, выяснилось, что если мы поместим каноническое из всех веб-сайтов, копирующих содержимое исходного URL-адреса, в этот исходный URL-адреса, результаты в поисковой выдаче поисковой системы будут следующими:
- название исходного URL
- описание исходного URL
- URL страны, в которой был выполнен поиск, который был каноничен исходной версии.
представьте себе сообщение, написанное на испанской версии автомобиля Гомера Симпсона, Plymouth Junkerolla 1986 г. Поскольку мы являемся распространенным средством массовой информации, этот контент публикуется на 100% в Аргентине и Мексике. Мы меняем названия и описания Гомера на Гомера и машины на машине или машине. Это единственное, что сделано.
Следуя предыдущему примеру, правильным будет то, что каждая из версий сделана канонической для себя, в дополнение к соответствующему hreflang.
Но в этом случае мы решили прицелиться с канонической версией Испании с постов Аргентины и Мексики, потому что мы считаем, что это оригинальная версия и остальные копии. Кроме того, таким образом, мы укрепили бы позицию испанской почты, испанской сети, которая нас интересует.
Это был бы пример.
Испания Аргентина Мексика Титул Лучший автомобиль в истории: Plymouth Junkerolla 1986 года Лучший автомобиль в истории: Plymouth Junkerolla 1986 года Лучший автомобиль в истории: 1986 Plymouth Junkerolla Описание Знает историю лучшего автомобиля в истории, Плимута Юнкеролла 1986 года, автомобиль Гомера Симпсона Я знаю историю лучшего автомобиля в истории, Плимут Юнкерола 1986 года, автомобиль Гомера Симпсона Знает историю лучшего автомобиля в истории, Плимут Юнкерола 1986 года, автомобиль Гомера Симпсон URL españa.com / coches argentina.com.ar/coches mexico.com.mx/coches Canonical A сама españa.com / coches españa.com / cars
Согласно результатам судебного разбирательства, в этом случае будут предложены следующие варианты.
- Если поисковая система находится в Испании, появится URL españa.com / cars с названием и описанием.
- Если поисковая система находится в Аргентине, появится название и описание испанской версии, но URL-адрес аргентинской версии.
- Если поисковая система находится в Мексике, появится название и описание испанской версии, но URL-адрес мексиканской версии.
Вот почему важно правильно решить, как устанавливаются канонические символы.
Эссе Серхио Редондо
Итак, мой партнер Серхио Редондо Он сделал тот же тест с похожими результатами. Это тест, в котором мы попытались увидеть, что происходит, когда в многострановом проекте канонический язык не соответствует hreflang локальной версии, в которой мы находимся (то есть канонические элементы указывают на исходный контент).
Результат Поиск Google .com:
- Название URL, который получает канонический (оригинальный URL)
- Описание URL, который получает канонический (оригинальный URL)
- URL локальной версии
- Кэш, который показывает, является кешем канонической страницы, тот, который получает канонический
Кроме того, второй эксперимент о том же задании: если значение x-default в hreflang не совпадает с каноническим URL, оно показывает нам следующее:
- Название URL, который получает канонический (оригинальный URL)
- Описание URL, который получает канонический (оригинальный URL)
- URL-адрес hrefllang x-default
- Кеш, который показывает, является кешем канонической страницы.
4. Канонический с усилителем
4.1. ампер
AMP (или «Ускоренные мобильные страницы») - это способ более быстрого отображения содержимого вашей веб-страницы, поскольку его цель - повысить производительность страниц (производительность и скорость) при использовании Интернета с мобильных устройств. Он монтируется вокруг 1) AMP HTML (минимальные компоненты), 2) AMP JS (минимальный код JavaScript) и 3) кешей (через CDN). Самая важная вещь с точки зрения этой статьи состоит в том, что у вас обычно есть контент AMP в вашем собственном домене, но у Google есть свой собственный URL, который появляется в новостном блоке (что делает вас 302, кстати)
4.2. Канонический + усилитель
Нет никакого изменения цели, так как каноническая директива должна применяться одинаково и с рабочего стола должна указывать на усилитель. Что произойдет с мобильным первым индексом, когда он выйдет? Без понятия
- версия усилителя прицеливания канонична настольной версии
- настольная версия, указывающая с помощью директивы rel amphtml на версию amp
- в случае, если Google показывает свой URL (нормальный), это, по умолчанию, имеет каноническое указание на версию нашего веб-сайта amp.
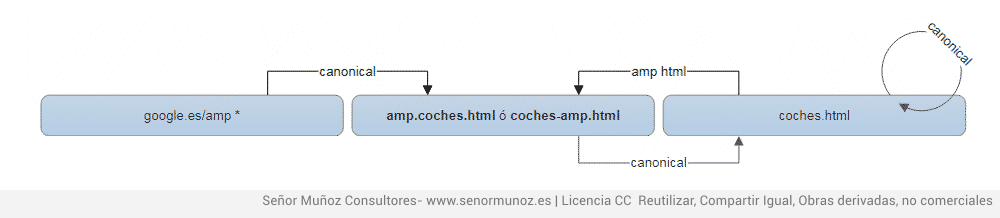
rel = canonical и html с URL-адресом Google, который отображается по умолчанию.
В этом примере показано, что делает версия Google amp (именно то, что появляется в поисковой выдаче). Это делает перенаправление 302 на канонический URL. Это не актуально, так как мы не можем это контролировать.
5. Canonical с мобильной версией
5.1. Мобильная версия
У нас может быть мобильная версия нашего веб-сайта, где мы представляем оптимизированный HTML для мобильных сервисов. Это соглашение (глаз, не написано, это как нажатие на логотип, который всегда приводит вас к дому), что мобильная версия сайта находится в поддомене m. основного домена, но это не обязательно (пока другие домены мы не видели для мобильной версии). В мобильной версии Интернета должен существовать тот же контент, но нам разрешены определенные лицензии, которых нет в версии для настольных компьютеров: мы можем скрыть элементы (если они присутствуют)
5.2. мобильный + канонический
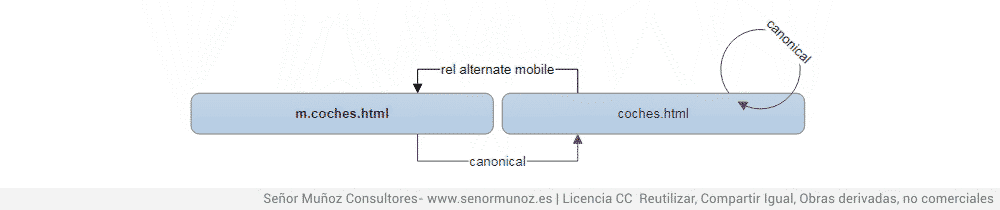
rel альтернативный мобильный и rel = канонический
5.3. Canonical с усилителем и мобильной версией
Сегодня возникает сложная ситуация, но, если она появляется, у нее есть простое решение, поскольку URL-адрес рабочего стола должен будет указывать с соответствующей альтернативой (мобильная версия и версия усилителя) на соответствующие URL-адреса и эти версии, в свою очередь, укажите канонически на рабочий стол, так как он является основным Почему не упоминается мобильная версия и версия усилителя? Потому что версия, которую должны иметь альтернативы, - это рабочий стол. m.coches.html не является мобильной альтернативой версии amp.coches.html (или наоборот).
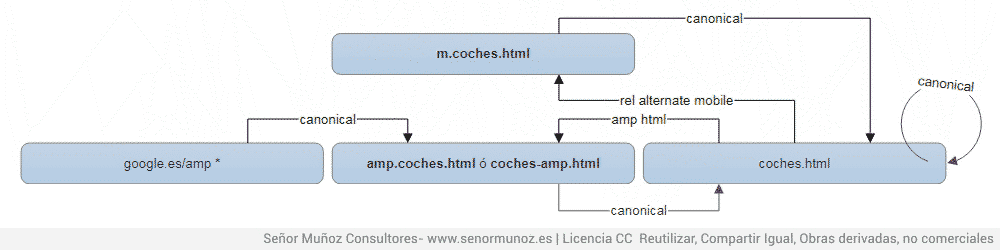
rel = "canonical", rel alternate mobille и rel amp html
6. Канонический с noindex
6.1. NOINDEX
Noindex на уровне цели просит Google не индексировать URL. Он используется против определенного контента, который не интересует нас для позиционирования, такого, который не интересует нас для индексации или перед очисткой URL-адресов panda, например, чтобы пометить эти URL-адреса низкого качества, ...
6.2. Noindex и канонический:
Так можно ли связать тег noindex и канонический тег в одном URL? Когда мы объединяем два тега в одном и том же URL-адресе, мы будем давать неверный сигнал поисковой системе: эй, не индексируйте меня, но эй, я оригинальный URL . Если вы хотите получить больше информации, вы можете проверить это сообщение в блоге, где мы говорим о том, что случилось с соединение noindex и канонического , Имея каноническое, то, что вы говорите поисковой системе, заключается в том, что два URL-адреса эквивалентны (как раз противоположность noindex).
Совет таков: не появляйтесь в одном и том же URL, выберите один из двух . Если вы хотите обеспечить индексацию проиндексированного URL-адреса, удалите канонический и отметьте его как noindex . Если у вас разные URL-адреса (два или более), а содержание равно на 100%, вы заинтересованы в вставке канонического кода, и если у вас есть URL-адреса, которые не интересуют вас для индексации, используйте noindex.
7. Канонический с robots.txt
В этом типе унификации мы обычно говорим о блокировке определенных URL через robots.txt. То есть поместите в файл robots.txt запрет: / someFolder
Как и в предыдущем пункте, не рекомендуется присоединять директиву disallow robots.txt к канонической. Если мы хотим поместить каноническую директиву в определенный URL-адрес, это связано с тем, что она создает ситуацию дублирования контента. Но если мы не дадим роботу доступ к этому URL, мы не узнаем, что там есть контент, который мы хотим «канонизировать» для некоторого URL. Если мы помечаем URL с помощью noindex через robots.txt или запрещаем поисковой системе доступ к этому URL, этот URL, который может быть уже проиндексирован Google, все равно будет ранжироваться по определенному ключевому слову.
Если мы что-то блокируем с помощью robots.txt, это потому, что мы не хотим, чтобы Google сканировал этот URL. Вопрос в том, что если я хочу, чтобы этот URL был проиндексирован? , Пример: представьте юридический URL-адрес предупреждения, который мы уже проиндексировали и хотим сохранить в индексе. Это делает каноническим для себя. Что происходит, так это то, что блокада так, что Google не ходит вокруг, поэтому я поставил запрет.
7.1. Приложение: Запрещает ли предотвращение индексацию?
Наличие тега noindex не препятствует индексации поисковыми системами. В следующем примере вы видите образец того, что мы вам говорим. Этот URL имеет помеченный noindex, он выполняет мета-обновление и 302 для нового URL, но он ранжируется (вероятно, авторитетом сайта), который я переписываю и обновляю: 20 июля 2017 года, чем в комментариях ( спасибо Кристиан, спасибо Хосе Мария Спасибо, Кико ) Говорим совершенно логичные вещи. Я изменяю заголовок на «Запретить» (перед тем, как поставить noindex)
URL с запрещением и ранквеандо в Google
Этот URL заблокирован файлом robots.txt. То есть: Google не может получить к нему доступ. Так что, если бы мы хотели использовать каноническое здесь, Google не мог бы видеть это.
В случае, если мы хотим канонизировать этот URL-адрес другим, нам потребуется 1) Вставить в этот URL каноническую директиву 2) Удалить запрет, чтобы Google ввел 3) Пусть Google обновит свой кэш и обнаружит канонический для правильного URL. И когда мы обнаружим, что Google уже показывает исходный URL, то 4) мы снова выставили бы запрет.
И если бы она была оригинальной и имела бы собственную ссылку на каноническое, мы бы не вывели ее из индекса (потому что это оригинал)
Похожие
Написание SEO контентаНаписание SEO контента не должно быть сложным. Существует множество ресурсов, которые помогут вам стать отличным автором контента для SEO. Самое главное, чтобы придумать творческие способы эффективного использования вашего ключевого слова - в конце концов, это основа SEO-написания! Но есть много других способов улучшить свои навыки письма для SEO. Для начала подумайте о своей аудитории. Кому ты пишешь? Какие вопросы Не позволяйте всему индексировать и сканировать: noindex, robots.txt и canonical
... rel = "canonical" href = "http://www.website.nl/beste-pagina" /> Об авторе: Эрик ван Лаар С начала 2011 года я работаю веб-редактором. предъявитель в области социальных сетей, SEO, миграции контента и веб-редактирования. Время от времени я пишу в блоге о событиях, которые меня поражают. Обучался как журналист и увлекался языком. Мне удалось выполнить различные интересные задания для самых разных клиентов. Некоммерческая Когда лучше Robots.txt Команды с производительностью Yoast ... | Pagup
Если вы являетесь пользователем WordPress, как компания или агентство, вы наверняка знаете Yoast SEO, возможно, один из лучших плагинов, доступных на WordPress, для оптимизации его контента и его органичной производительности в поисковых системах. Вот почему, при разработке плагина Better Robots.txt, мы естественным образом думали о том, чтобы ассоциировать себя с лучшим предложением ... лучшим из оптимизации. Поскольку это все об этом, оптимизируйте свой сайт, чтобы получить максимальную Синдикация контента 101
... словам одного оценка от Курата «Целевой набор маркетингового контента по контент-маркетингу суперзвезды создан на 65%, курируется на 25% и синдицированный контент <10%». Вы знаете, насколько важен оригинальный контент, и курируемый контент это способ сэкономить время для продвижения вашего сайта. Но как NoIndex, NoFollow SEO Overkill
... используют теги «noindex», чтобы робот поисковых систем не индексировал определенную страницу на сайте"> SEO используют теги «noindex», чтобы робот поисковых систем не индексировал определенную страницу на сайте. Мы используем теги «nofollow», чтобы предотвратить прохождение рейтинга страницы через определенную ссылку на страницу, на которую ссылаются (иначе говоря, «разведение ботов», «моделирование ранга страницы» и т. Д.). Ничего плохого нет ни в одном из этих приемов, но я часто Как произошел упадок веб-каталогов?
Как работает поисковая система?
Хотя вы всегда должны создавать контент сайта, ориентированный на ваших клиентов, а не на поисковые системы, важно понимать, как работает поисковая система. Как только вы это знаете, вы можете перейти к следующему шагу, который включает в себя элементы, которые Как включить поисковые движки
На этой неделе мы расскажем, как включить URL-адреса, удобные для поисковых систем (SEF) в Joomla. Этот мистический подвиг не требует расширений! Вот как вы это делаете: Перейдите в раздел «Администрирование» вашего сайта Joomla и «Глобальная конфигурация» (или в меню «Сайт»> «Глобальная конфигурация»). В настройках «Сайта», справа вы увидите «Настройки SEO», нажмите кнопку «Да», чтобы включить удобные для поисковых систем URL. В чем разница между копирайтером и автором контента?
... ��я? Мы делаем их профессиональные цифры более понятными Копирайтер и автор контента : две фигуры, которые часто путают, чьи функции, хотя и выполняются в одном и том же контексте и одинаково важны, не одинаковы. Вы хотите, потому что в некоторых случаях термины, выраженные в определенной идиоме, имеют более конкретное значение, чем то, что понимается, когда вы начинаете использовать их в стране, где говорят Фрагмент: цитаты, дубликаты контента и SEO
... ированный контент и SEO продолжает оставаться предметом обсуждения, особенно в свете продолжающихся обновлений поиска Google"> Дублированный контент и SEO продолжает оставаться предметом обсуждения, особенно в свете продолжающихся обновлений поиска Google. Если вы беспокоитесь о цитировании великого источника в вашем веб-маркетинг Как стать экспертом по SEO
Чтобы стать экспертом по SEO, вам нужно научиться искусству поисковой оптимизации. Это процесс ранжирования веб-сайта в Google, чтобы он показывался в первых строчках по целевым ключевым словам. Основная причина, по которой вы хотите ранжировать веб-сайт в верхних позициях, заключается в том, что страницы или веб-сайты на этих позициях получают большую часть трафика по этому ключевому слову. Если веб-сайт находится на второй странице или дальше, он почти не получит никакого трафика. Итак,
Комментарии
Как они относятся к другим членам сообщества, когда они создают беседы вокруг контента, который вы публикуете или обсуждаете?Как они относятся к другим членам сообщества, когда они создают беседы вокруг контента, который вы публикуете или обсуждаете? Ответы на эти два вопроса позволят вам изучить «скрытые» ключевые слова, которые передают высокопрофильный и качественный трафик. Этот набор ключевых слов является стратегическим не только для того, чтобы поразить вашу аудиторию, но и для поиска аналогичных рыночных ниш, в которых вы можете показать продукт или услугу, которую вы продаете. SEO Знают ли они, что они ожидают от вас, и можете ли вы ответить на них идеально?
Знают ли они, что они ожидают от вас, и можете ли вы ответить на них идеально? Если ответ отрицательный, я могу только рекомендовать вам исследовать и анализировать до тех пор, пока вы не проясните ситуацию, потому что до тех пор, пока вы не будете уверены, что вы не сможете создать последовательную онлайн-стратегию, а тем более стратегию SEO (а также тему, тон и формат содержание является важной частью обоих пунктов). Итак, знайте свою аудиторию, обеспечьте техническую часть и Знаете ли вы, что делают ваши SEO-конкуренты, как они ранжируются в Google, и сколько трафика они получают?
Знаете ли вы, что делают ваши SEO-конкуренты, как они ранжируются в Google, и сколько трафика они получают? Знание этой информации может быть разницей между будущим успехом или провалом SEO. Вот почему конкурентный анализ является важным шагом при разработке вашей стратегии SEO. В этой главе рассматриваются некоторые инструменты конкурентного анализа SEO, которые могут помочь вам ответить на все (или большинство) ваших вопросов и предоставить вам наиболее точные данные Что такое синдикация контента, как она работает и как ее успешно выполнить?
Что такое синдикация контента, как она работает и как ее успешно выполнить? Синдикация контента: обзор Изображение через Flickr Майкларрингтон Проще говоря, синдикация контента когда вы разрешаете другим сайтам публиковать ваши работы, Как интеграция динамического контента в серверной части CMS работает как WordPress?
Как интеграция динамического контента в серверной части CMS работает как WordPress? Существуют значительные различия между отдельными CMS. В WordPress функции для интеграции динамического контента частично связаны с темами. Альтернативно, функциональность может быть модифицирована с помощью плагинов (например, для собственных Taaxonomies, посттипов и фильтров). С другими CMS, такими как TYPO3, функциональность должна быть интегрирована разработчиком с типом script в шаблон. Поможет ли это ключевое слово пользователям вашего сайта найти то, что они искали, и удовлетворит ли полученный результат?
Поможет ли это ключевое слово пользователям вашего сайта найти то, что они искали, и удовлетворит ли полученный результат? Будут ли эти посетители приносить вам прибыль (или помогут в достижении других целей)? 2) Анализировать результаты по слову в основных поисковых системах Чтобы понять, насколько конкурентоспособным является слово и насколько легко или сложно будет получить ваш сайт на первых позициях в поиске с помощью этого слова, необходимо проанализировать Работаете ли вы с клиентами, которые спрашивают вас, как они могут улучшить свой сайт и увеличить трафик?
Работаете ли вы с клиентами, которые спрашивают вас, как они могут улучшить свой сайт и увеличить трафик? Просто введите URL-адрес сайта, который вы хотите проанализировать, в раздел «Аналитика домена», и SEMrush предоставит вам обзор как органического, так и платного трафика, ключевых слов, по которым вы получаете рейтинг, ежемесячного объема поиска, который они получают, и какие позиции в Google вы держите, ваши основные конкуренты и кто ссылается на ваш сайт. Тот факт, Во-вторых, вы действительно знаете, действительно ли существует 100 поисковых систем и полезны ли они?
Во-вторых, вы действительно знаете, действительно ли существует 100 поисковых систем и полезны ли они? Будет ли ваша аудитория когда-либо использовать эти 100 поисковых систем? Один простой и прямой ответ на этот вопрос - «Нет». Никто не использует более 3 или 4 поисковых систем. И ваш сайт не нуждается в представлении в более чем 2 или 3 популярных поисковых системах. Просто попросите компанию, которую вы планируете нанять, составить список по крайней мере из 10 популярных поисковых систем, Они игнорируются как другие функции?
Они игнорируются как другие функции? Ответ: да. Они будут рассматриваться как символ и игнорироваться, хотя они могут быть специально для поиска. Это не было бы полезным содержанием в одиночку. Как и любые другие символы, им не приписывается смысловой смысл. Английский веб-мастер Hang Out: 19 сентября 2017 Вот мои заметки и рассказы, сделанные на этой неделе. Я включил заданный вопрос, краткое изложение ответа Джона Мюллера и мои собственные заметки и ссылки, Будет ли приложение иметь частичную или полную веб-четность (контент в приложении такой же, как контент на веб-сайте)?
Будет ли приложение иметь частичную или полную веб-четность (контент в приложении такой же, как контент на веб-сайте)? Глубокая связь Глубокая связь с приложением ведет себя как URL. Глубокая ссылка направляет на определенный экран (страницу) в приложении. Глубокие ссылки на Android и iOS выглядят по-разному. Android : android-app://com.example.android/example/ iOS : http://www.yourdomain.com/example Помимо вопроса, есть ли у них полный отдел SEO, как вы можете определить, есть ли у них опыт SEO, который вам нужен?
Помимо вопроса, есть ли у них полный отдел SEO, как вы можете определить, есть ли у них опыт SEO, который вам нужен? Вот семь вопросов, чтобы задать ... Какой процент ваших счетов вы бы отнесли к работе SEO? Прямой вопрос, конечно, но он дает им понять, что вы серьезно относитесь к SEO. И это говорит вам, если они специализируются на SEO или если они делают первоначальные конфигурации сайта SEO, и тогда вы по своему усмотрению. Сколько у вас преданных
7.1. Приложение: Запрещает ли предотвращение индексацию?
Что произойдет с мобильным первым индексом, когда он выйдет?
7.1. Приложение: Запрещает ли предотвращение индексацию?
Кому ты пишешь?
Как работает поисковая система?
В чем разница между копирайтером и автором контента?
?я?
Как они относятся к другим членам сообщества, когда они создают беседы вокруг контента, который вы публикуете или обсуждаете?
Знают ли они, что они ожидают от вас, и можете ли вы ответить на них идеально?
Знаете ли вы, что делают ваши SEO-конкуренты, как они ранжируются в Google, и сколько трафика они получают?